タップできるもくじ
【kaggle入門】データ理解:2変数間の散布図で関係性を把握
kaggleにトライする際、いきなりデータモデルを作成するのではなく、まずはデータの内容を理解する事が重要です。
このエントリーでは、2変数間の散布図をまとめて作成して、全体の項目同士の関係性をざっと把握する方法を記載します。
記事を書いた人
元営業という経歴を活かしながら、金融・製造・流通業のお客様を中心にAI活用コンサルや定着支援・人材育成の支援をしたり、講演や執筆活動など幅広く活動しています。
ヤエリ(@yaesuri_man)
普段のお客様との会話の中でよく話題に出るこのテーマ。
技術畑ではないものの、長らく現場の実務に携わってきた視点は喜ばれることが多いです。
使用するデータ
今回使用したのは、kaggleの古典的問題「Titanic: Machine Learning from Disaster」です。

Titanic号の乗客データを元に、誰が生き残るかを予測するというもの。
以降、イチからまとめてみたいと思います。
具体的なコーディング例
必要なライブラリの読み込み
まずはデータ可視化ライブラリ「Matplotlib」を「plt」として読み込みます。
# 必要なライブラリの読み込み import matplotlib.pyplot as plt
train.csvの読み込み
あらかじめ用意されているtrainデータ「train.csv」を「df_train」として読み込みます。
# train.csvを「df_train」として読み込む。0列目のcol(id)がindex
df_train = pd.read_csv('../input/train.csv', index_col=0)
ヘッダーの確認
読み込んだ「df_train(=train.csv)」のヘッダー情報をざっと確認してみます。
# ヘッダーの確認 df_train.head()
▼クリックで拡大▼

SurvivedやPclass、Name、Sex、Ageといった特徴量が11個あることが分かります。
(Passengeridはindex)
特徴量間の散布図の作成
特徴量間の散布図を作成してみます。
# 特徴量間の散布図を作成してみる pd.plotting.scatter_matrix(df_train[['Survived', 'Pclass', 'Name', 'Sex', 'Age', 'SibSp', 'Parch', 'Ticket', 'Fare', 'Cabin', 'Embarked']]) plt.tight_layout() plt.show()
▼クリックで拡大▼
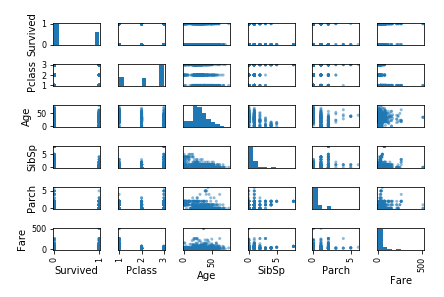
散布図が右肩上がりになれば正の相関、右下下がりになれば負の相関があるはずなのですが、残念ながら今回の特徴量間には強い相関は見られないようです。
【kaggle入門】データ理解:2変数間の散布図で関係性を把握まとめ
ここまでの全コードをまとめると以下です。
# 必要なライブラリの読み込み
import matplotlib.pyplot as plt
# train.csvを「df_train」として読み込む。0列目のcol(id)がindex
df_train = pd.read_csv('../input/train.csv', index_col=0)
# ヘッダーの確認
df_train.head()
# 特徴量間の散布図を作成してみる
pd.plotting.scatter_matrix(df_train[['Survived', 'Pclass', 'Name', 'Sex', 'Age', 'SibSp', 'Parch', 'Ticket', 'Fare', 'Cabin', 'Embarked']])
plt.tight_layout()
plt.show()
その他、pythonやkaggle、AI・機械学習といった記事のまとめはこちらです。
-

-
プログラミング関連の記事まとめ
続きを見る
ここからは、実際に私が購入し、おすすめできると思った本やオンラインスクールを紹介します。
機械学習のための「前処理」入門
まずはこちら。「機械学習のための『前処理』入門」です。
- これから機械学習を始めてみたい
- kaggleやSIGNATEにチャレンジしてみたい
という方には最適な本で、個人的には一番のおすすめです。
データモデルの精度向上には特徴量エンジニアリングが不可欠、というよりこれが全てと言っても過言ではありません。
各種環境準備の方法やコーディングの詳細に至るまで、誰にでも分かりやすく書かれています。
この一冊さえあれば、とりあえずkaggleにトライすることができます。
Udemy「みんなのAI講座 ゼロからPythonで学ぶ人工知能と機械学習」
ベネッセが主催する、プログラミング未経験者を対象にしたコース。
数学や統計的な知識はそこそこに、文字通り人工知能と機械学習をゼロから学習できます。
受講生2万人以上、4千人以上の評価者から、5段階中4.0の評価を得ている、万人におすすめできる優良講座。
定価15,000円と高価ですが、90%OFFといったキャンペーンを頻繁に行っていますので、それを狙うのがおすすめ。
人工知能は人間を超えるか
pythonのコーディングからは離れますが、もしこの本を読んでいない人がいたら必ず一度は目を通しておいた方が良いです。
この界隈では有名な、東大の松尾豊先生の著書「人工知能は人間を超えるか」。
いわゆるAI・人工知能、機械学習といった昨今のキーワードを中心に、過去の歴史からここ最近の動き、今後の動向に至るまでを、平易な表現で丁寧に解説されています。
また日本ディープラーニング協会が開催する「ディープラーニング ジェネラリスト検定(通称:G検定)」の推薦図書の一つでもあります。
全てのビジネスマンにおすすめできる一冊。中古でもkindleでも構いませんので、これだけは目を通しておいた方が良いです。