タップできるもくじ
【kaggle入門】indexを無視してデータフレーム同士を結合する方法
indexを無視してデータフレームを結合する方法です。
記事を書いた人
元営業という経歴を活かしながら、金融・製造・流通業のお客様を中心にAI活用コンサルや定着支援・人材育成の支援をしたり、講演や執筆活動など幅広く活動しています。
ヤエリ(@yaesuri_man)
普段のお客様との会話の中でよく話題に出るこのテーマ。
技術畑ではないものの、長らく現場の実務に携わってきた視点は喜ばれることが多いです。
事象
kaggleでモデリングして予測した後、その結果を新たに読み込んだsumple_submission(元はsumple_submission.csv)に転記してsubmitする際に、お互いのindexを参照してしまいうまく結合できない、ということがあります。
やりたいこと
図で表すと以下の通り。予測結果のindexは無視し、sample_submissionのindexを残して、単純に結合したい、という場面が出てきます。
▼クリックで拡大▼

うまくいかないと、こうなる
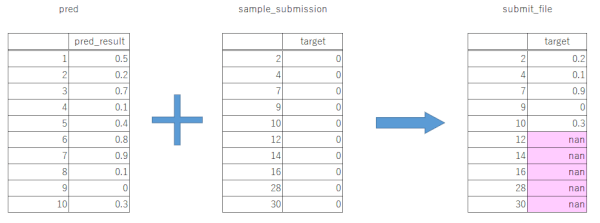
要はお互いのindexを参照してマッチングしてしまい、マッチしなかった所がnanで埋まってしまうため、submit時にエラーが出る形です。
結合の仕方
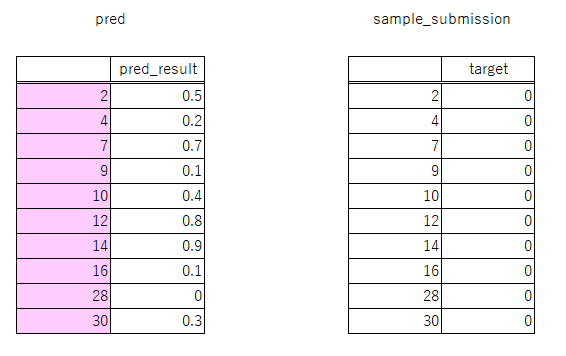
やり方としては、事前にモデリングした予測結果のindexをsample_submissionのindexに置き換えます。
モデリングした予測結果のindexをsample_submissionのindexに置き換える
# モデリングした予測結果のindexをsample_submissionのindexに置き換える pred.index = submissionfile.index
こうすると以下のように、予測結果の「pred」データフレームのindexが置き換わります。
予測結果をsample_submissionファイルに入れる
# 予測結果をsample_submissionファイルに入れる sample_submission['target'] = pred
▼クリックで拡大▼
【kaggle】indexを無視してデータフレーム同士を結合する方法まとめ
過去のサンプルを元に、今回のコード全体をおさらいしてみます。
-

-
【kaggle入門】XGBoostによる最もシンプルな回帰モデル構築
続きを見る
# おやくそく(各種ライブラリの読み込み)
import numpy as np
import scipy as sp
import pandas as pd
from pandas import DataFrame, Series
import category_encoders as ce
import xgboost as xgb
from sklearn.model_selection import GridSearchCV
# データの読み込み
df_train = pd.read_csv('../input/train.csv', index_col=0)
df_test = pd.read_csv('../input/test.csv', index_col=0)
# 学習データの分離
y_train = df_train.ターゲット変数
x_train = df_train.drop(['ターゲット変数'], axis=1)
x_test = df_test
# 文字列のエンコード
cats = []
for col in x_train.columns:
if x_train[col].dtype == 'object':
cats.append(col)
oe = ce.OrdinalEncoder(cols=cats, return_df=False)
x_train[cats] = oe.fit_transform(x_train[cats])
x_test[cats] = oe.transform(x_test[cats])
# 欠損値の補完
x_train=x_train.fillna(x_train.median())
x_test=x_test.fillna(x_test.median())
# モデリング
xgb_model = xgb.XGBRegressor()
reg_xgb = GridSearchCV(xgb_model,
{'max_depth': [2,4,6],
'n_estimators': [50,100,200]}, verbose=1)
reg_xgb.fit(x_train, y_train)
# 予測
pred = pd.DataFrame( {'XGB': reg_xgb.predict(x_test)})
# 投稿用csvの生成
submissionfile = pd.read_csv('../input/sample_submission.csv', index_col=0)
# モデリングした予測結果のindexをsample_submissionのindexに置き換える pred.index = submissionfile.index
submissionfile['ターゲット変数'] = pred
# 予測結果をsample_submissionファイルに入れる
sample_submission['ターゲット変数'] = pred
# submit用csvを生成する
submissionfile.to_csv('./submissionfile.csv')
その他、pythonやkaggle、AI・機械学習といった記事のまとめはこちらです。
-
-
プログラミング関連の記事まとめ
続きを見る
ここからは、実際に私が購入し、おすすめできると思った本やオンラインスクールを紹介します。
機械学習のための「前処理」入門
まずはこちら。「機械学習のための『前処理』入門」です。
- これから機械学習を始めてみたい
- kaggleやSIGNATEにチャレンジしてみたい
という方には最適な本で、個人的には一番のおすすめです。
データモデルの精度向上には特徴量エンジニアリングが不可欠、というよりこれが全てと言っても過言ではありません。
各種環境準備の方法やコーディングの詳細に至るまで、誰にでも分かりやすく書かれています。
この一冊さえあれば、とりあえずkaggleにトライすることができます。
Udemy「みんなのAI講座 ゼロからPythonで学ぶ人工知能と機械学習」
ベネッセが主催する、プログラミング未経験者を対象にしたコース。
数学や統計的な知識はそこそこに、文字通り人工知能と機械学習をゼロから学習できます。
受講生2万人以上、4千人以上の評価者から、5段階中4.0の評価を得ている、万人におすすめできる優良講座。
定価15,000円と高価ですが、90%OFFといったキャンペーンを頻繁に行っていますので、それを狙うのがおすすめ。
人工知能は人間を超えるか
pythonのコーディングからは離れますが、もしこの本を読んでいない人がいたら必ず一度は目を通しておいた方が良いです。
この界隈では有名な、東大の松尾豊先生の著書「人工知能は人間を超えるか」。
いわゆるAI・人工知能、機械学習といった昨今のキーワードを中心に、過去の歴史からここ最近の動き、今後の動向に至るまでを、平易な表現で丁寧に解説されています。
また日本ディープラーニング協会が開催する「ディープラーニング ジェネラリスト検定(通称:G検定)」の推薦図書の一つでもあります。
全てのビジネスマンにおすすめできる一冊。中古でもkindleでも構いませんので、これだけは目を通しておいた方が良いです。