タップできるもくじ
kaggleでデータ概要をざっと把握する方法~pandas-profilingが超便利~

kaggleのコンペに参戦する際にまず大事なのは、与えられたデータの内容を確認して、理解をすること。
これまで以下のような方法を紹介しましたが、もっと簡単に、網羅的に概要を表示させることができるコードをご紹介します。
-

-
【kaggle入門】データ理解:2変数間の散布図で関係性を把握
続きを見る
記事を書いた人
元営業という経歴を活かしながら、金融・製造・流通業のお客様を中心にAI活用コンサルや定着支援・人材育成の支援をしたり、講演や執筆活動など幅広く活動しています。
ヤエリ(@yaesuri_man)
普段のお客様との会話の中でよく話題に出るこのテーマ。
技術畑ではないものの、長らく現場の実務に携わってきた視点は喜ばれることが多いです。
kaggleでデータ概要をざっと把握する方法 pandas-profiling
その方法は「pandas-profiling」です。
pandas-profilingの準備
クライアントで利用する場合は、Anacondaやpromptからインスト―ルしておきましょう。
「スタート」→「Anaconda3(64-bit)」→「Anaconda Prompt(Anaconda3)」を開いて・・・
以下を入力。
pip install pandas-profiling
なお、私のようにpythonを「C:¥Program Files (x86)」にインストールしている方は、上記ではエラーが出ます(管理者権限がないと書き込みできない)。
そのため、以下のように「--user:¥」オプションをつけてインストールします。
pip install pandas-profiling --user
pandas-profilingの使用方法
使い方は簡単です。
kaggleのTitanicのデータで解説します。
まずは呼び出し。
import pandas as pd import pandas_profiling as pdp
trainとtestデータ(csv)をデータフレームに読み込み
train_df = pd.read_csv('../input/train.csv')
test_df = pd.read_csv('../input/test.csv')
以下コードを入力するだけです。
pdp.ProfileReport(train_df)
すると、以下のようにデータの概要が一気に表示されます。
Overview
データの超概要です。
特徴量数やサイズ、各特徴量のエラー(欠損やゼロ値など)が表示されます。

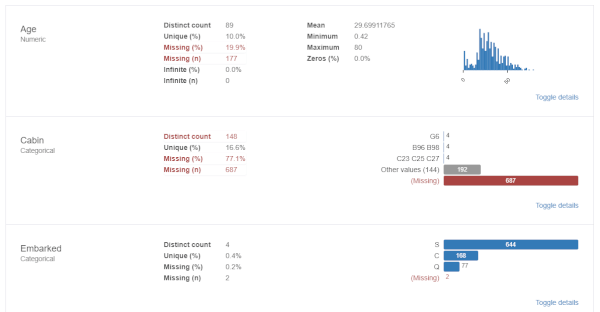
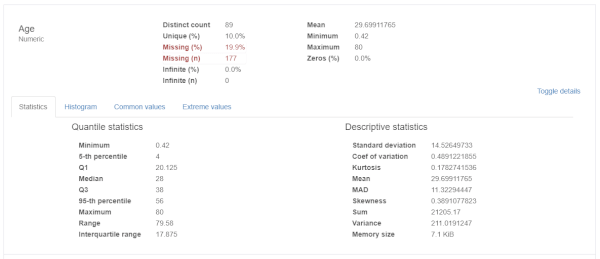
Variables
各特徴量ごとのデータの詳細や、分布などを確認できます。
右下の「Toggle detail」を選択すると、更に詳細が表示されます。
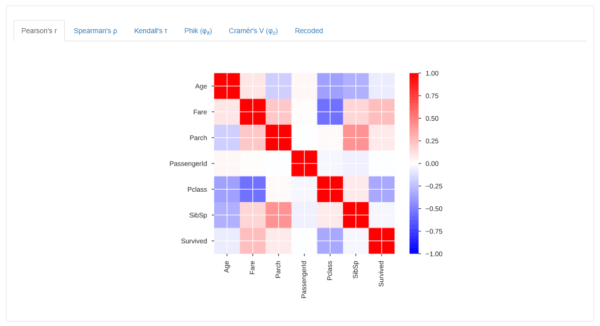
Correlations
「Correlations」=「相関関係」。各特徴量毎の相関を見る事ができます。
赤は正の相関、青は負の相関で、色が濃ければ濃いほど強い相関があるということです。
Missing values
各特徴量ごとの欠損の数や分布を見る事ができます。
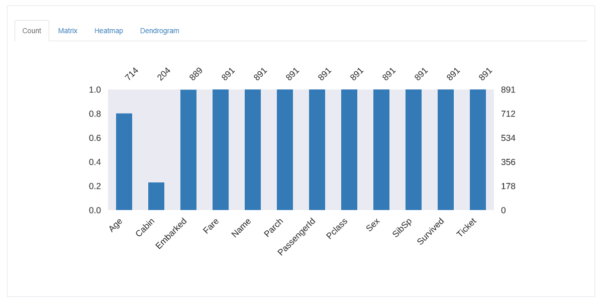
これによると、
- 「Age」と「Cabin」に欠損がある
- それ以外には欠損は無い
事が分かります。
※それ以外は全てグラフが埋まっているため
さらにメニューの「Matrix」を選択すると、全IDの連番のうち、どの部分に欠損があるかの分布を表示させることができます。
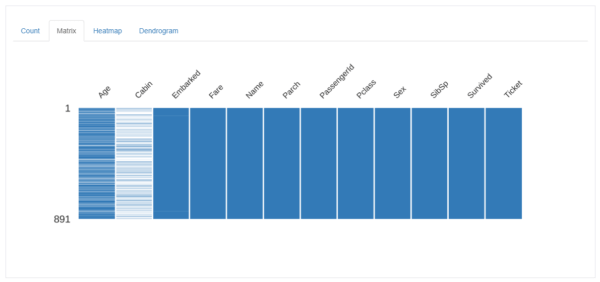
AgeもCabinも綺麗なストライプになっていますので、欠損部分は固まっておらず、分布していることが分かります。
Sample
データの冒頭10行と、最後の10行が表示されています。
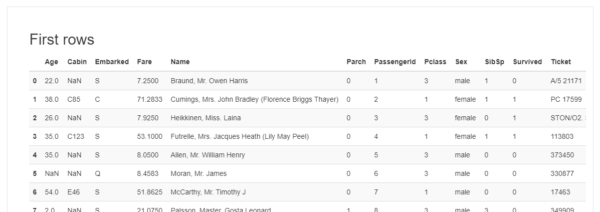
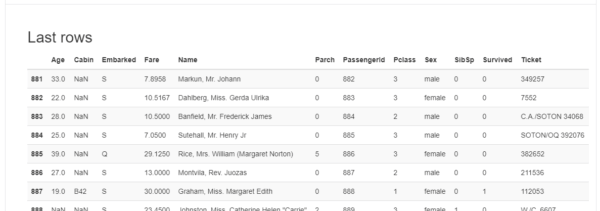
「pandas-profiling」利用時の注意点
注意点は一つだけ。
クライアントで処理をする場合、データ量によっては非常に時間がかかる点です。
ということも起こり得ますので、ご注意ください。
kaggleでデータ概要をざっと把握する方法まとめ
最後に、ここまでのコードをまとめます。
import pandas as pd
import pandas_profiling as pdp
train_df = pd.read_csv('../input/train.csv')
test_df = pd.read_csv('../input/test.csv')
pdp.ProfileReport(train_df)
その他、pythonやkaggle、AI・機械学習といった記事のまとめはこちらです。
-

-
プログラミング関連の記事まとめ
続きを見る
ここからは、実際に私が購入し、おすすめできると思った本やオンラインスクールを紹介します。
機械学習のための「前処理」入門
まずはこちら。「機械学習のための『前処理』入門」です。
- これから機械学習を始めてみたい
- kaggleやSIGNATEにチャレンジしてみたい
という方には最適な本で、個人的には一番のおすすめです。
データモデルの精度向上には特徴量エンジニアリングが不可欠、というよりこれが全てと言っても過言ではありません。
各種環境準備の方法やコーディングの詳細に至るまで、誰にでも分かりやすく書かれています。
この一冊さえあれば、とりあえずkaggleにトライすることができます。
Udemy「みんなのAI講座 ゼロからPythonで学ぶ人工知能と機械学習」
ベネッセが主催する、プログラミング未経験者を対象にしたコース。
数学や統計的な知識はそこそこに、文字通り人工知能と機械学習をゼロから学習できます。
受講生2万人以上、4千人以上の評価者から、5段階中4.0の評価を得ている、万人におすすめできる優良講座。
定価15,000円と高価ですが、90%OFFといったキャンペーンを頻繁に行っていますので、それを狙うのがおすすめ。
人工知能は人間を超えるか
pythonのコーディングからは離れますが、もしこの本を読んでいない人がいたら必ず一度は目を通しておいた方が良いです。
この界隈では有名な、東大の松尾豊先生の著書「人工知能は人間を超えるか」。
いわゆるAI・人工知能、機械学習といった昨今のキーワードを中心に、過去の歴史からここ最近の動き、今後の動向に至るまでを、平易な表現で丁寧に解説されています。
また日本ディープラーニング協会が開催する「ディープラーニング ジェネラリスト検定(通称:G検定)」の推薦図書の一つでもあります。
全てのビジネスマンにおすすめできる一冊。中古でもkindleでも構いませんので、これだけは目を通しておいた方が良いです。