機械学習で奥さんの浮気を予測してみた
今年度よりpythonによる機械学習のを学習中。
ネットで浮気調査のデータを見つけたので、こちらを元にデータモデルを作成し、実際に私の嫁の浮気を予測してみました。
kaggleのタイタニックを終えたあたりの人におすすめの内容です。
記事を書いた人
元営業という経歴を活かしながら、金融・製造・流通業のお客様を中心にAI活用コンサルや定着支援・人材育成の支援をしたり、講演や執筆活動など幅広く活動しています。
ヤエリ(@yaesuri_man)
普段のお客様との会話の中でよく話題に出るこのテーマ。
技術畑ではないものの、長らく現場の実務に携わってきた視点は喜ばれることが多いです。
データセット

1974年とかなり古いですが、イエール大学が行った浮気アンケート調査のデータです。
妻の年齢や学歴、職業、子供の人数等情報に加え、浮気経験有無が入っていますので、こちらを元に機械学習でモデルを作っていきたいと思います。
上記ページには色々なデータセットが載っていますが、中央下部右側の「affairs.txt」が対象データになります。
直接リンクは以下。
データの説明
2つ目の英語の論文のP10にカラム名の説明があります。
英語ですがそれ程難しくはないです。
データの確認
txtをExcelに読み込むと、初めの601行が15列、後ろの6,366行が14列となっていますので、量の多い6,366行のほうを使用します。
論文に書かれているデータの説明は以下の通り。
| No | 名称 | 説明 |
|---|---|---|
| 1 | ID | |
| 2 | constant | ※未使用 |
| 3 | v1 | 幸福度(1:悪い~5:良い) |
| 4 | v2 | 年齢 |
| 5 | v3 | 結婚年数 |
| 6 | v4 | 子供の数 |
| 7 | v5 | 信仰度(1:無宗教~4:強い) |
| 8 | v6 | 最終学歴 (9:小学校、12:高校、14:一部の大学、16:大卒、 17:一部の大学院、20:高度な学位) |
| 9 | not used | ※未使用 |
| 10 | v7 | 妻の職業 (1:学生、2:農業、3:ホワイトカラー、 4:教師・カウンセラー・ソーシャルワーカー・看護士・芸術家・作家・技術者、 5:管理職、6:高度な専門家) |
| 11 | v8 | 夫の職業(上の妻の職業と同様) |
| 12 | yRB | 不倫の指標 (不倫した相手の人数÷結婚年数) |
| 13 | not used | ※未使用 |
| 14 | not used | ※未使用 |
つまりyRB:過去に不倫した相手の人数÷婚姻年数 の値がポイントです。
この値が大きければ大きい程ヤバイ奥さんということになります。
ちなみにデータの最大値は57.6。
この方は結婚して2年半なので、その間に144人もの男性と不倫したと自己申告をしているという恐ろしい方です。
前処理
欠損の無い綺麗なデータのため特に前処理などは必要無いと思います。
私はExcel上で以下の特徴量を加えました。
| 特徴量名 | 意味 | 式 |
|---|---|---|
| first_marriage_age | 初婚年齢 | 年齢-結婚年数 |
| target | 不倫有無 | 不倫指標≠0なら、1 |
生データの不倫指標は分かりづらいため、0 or 1のカテゴリ変数として「target(不倫有無)」を加え、これを予測ターゲットとしました。
0なら浮気実績無し。1なら浮気実績ありということです。
上記データをExcelで相関分析した結果が以下です。
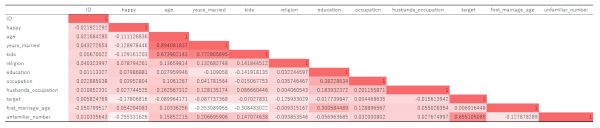
これを見る限りでは、ターゲットと強い相関のある特徴量は見い出せませんでした。
嫁の特徴量
一方、私の奥さんの特徴量は以下です。
| カラム名 | 嫁の属性 | 値 |
|---|---|---|
| ID | 適当に入力 | 99999 |
| happy | たぶん幸福度はMAXと思いたい | 4 |
| age | 39歳 | 39 |
| years_married | 結婚15周年 | 15 |
| kids | 子供2人 | 2 |
| religion | 無宗教 | 1 |
| education | 14に近しい学歴 | 14 |
| occupation | カテゴリ4に近しい職業 | 4 |
| husbands_occupation | 高度な専門化と思いたい | 6 |
| first_marriage_age | 24歳 | 24 |
上記データを「test.csv」としてtrainと同ディレクトリに配置します。
データモデル作成と予測
前処理が終わったところでいよいよデータモデル作成にとりかかります。
pythonをインストールしていない人はこちらをどうぞ。
-

-
Python挑戦記1 まずはPythonのインストール
続きを見る
実際に私が書いたコードは以下の通り。
と言ってもただデータを読み込み、列を定義してLightGBMに突っ込んだだけです。
※冗長だったり間違いがあると思いますので、是非ご指摘をお願いします。
#必要なライブラリの読み込み
import numpy as np
import scipy as sp
import pandas as pd
from sklearn.metrics import roc_auc_score
from sklearn.model_selection import StratifiedKFold
from tqdm import tqdm_notebook as tqdm
import lightgbm as lgb
from lightgbm import LGBMClassifier
import matplotlib.pyplot as plt
plt.style.use('ggplot')
%matplotlib inline
#trainとtestをそれぞれ'df_train','df_test'として読み込む
#※私はjupyter notebookのインストールフォルダと同じディレクトリに'data'というフォルダを置き、
#その中に'uwaki'というディレクトリを作成しtrain&testデータを配置しましたが、ここは適宜読み代えて下さい。
df_train = pd.read_csv('data/uwaki/train.csv', index_col=0)
df_test = pd.read_csv('data/uwaki/test.csv', index_col=0)
#trainデータをターゲットとそれ以外に分ける
#df_testもx_testにする
y_train = df_train['target']
x_train = df_train.drop(['target'], axis=1)
x_test = df_test
#交差検定でモデルの精度を見てみる
scores = []
skf = StratifiedKFold(n_splits=5, random_state=1, shuffle=True)
for i, (train_ix, test_ix) in enumerate(tqdm(skf.split(x_train, y_train))):
x_train_, y_train_ = x_train.values[train_ix], y_train.values[train_ix]
x_val, y_val = x_train.values[test_ix], y_train.values[test_ix]
clf = LGBMClassifier(boosting_type='gbdt', class_weight=None, colsample_bytree=0.71,
importance_type='split', learning_rate=0.05, max_depth=-1,
min_child_samples=20, min_child_weight=0.001, min_split_gain=0.0,
n_estimators=9999, n_jobs=-1, num_leaves=31, objective=None,
random_state=71, reg_alpha=1.0, reg_lambda=1.0, silent=True,
subsample=0.9, subsample_for_bin=200000, subsample_freq=0)
clf.fit(x_train_, y_train_, early_stopping_rounds=200, eval_metric='auc', eval_set=[(x_val, y_val)])
y_pred = clf.predict_proba(x_val)[:,1]
score = roc_auc_score(y_val, y_pred)
scores.append(score)
print('CV Score of Fold_%d is %f' % (i, score))
#LightGBMでモデルを作成する
gb = LGBMClassifier(boosting_type='gbdt', class_weight=None, colsample_bytree=0.71,
importance_type='split', learning_rate=0.05, max_depth=-1,
min_child_samples=20, min_child_weight=0.001, min_split_gain=0.0,
n_estimators=9999, n_jobs=-1, num_leaves=31, objective=None,
random_state=1, reg_alpha=1.0, reg_lambda=1.0, silent=True,
subsample=0.9, subsample_for_bin=200000, subsample_freq=0)
#LightGBMにx_train,y_trainのデータを入れる
gb.fit(x_train, y_train)
#x_testの値を入れ、予測してみる
pred = gb.predict_proba(x_test)[:,1]
#予測結果を表示する
pred
予測結果
- モデルのAUC:0.756
- 嫁の浮気確率:0.6006
データモデルのAUC=0.756という値は、予測テーマにもよりますが、実務上十分運用に耐えうる精度です(つまり確からしいデータモデルと言えます)。
浮気確率は0から1の間を取ります。
つまり確からしいデータモデルが0.6(60%)と言っているということです。
私には少々ショックな結果でした。。。
機械学習で奥さんの浮気を予測してみたまとめ
少し冷静になって、Random Forestでfeature_importancesを調べてみました。
各特徴量の中で浮気に効いている因子は以下の通りです。
- 幸福度が低ければ低いほど浮気しやすい
- 信仰度が低ければ低いほど浮気しやすい
- 結婚してからの期間が長い程浮気しやすい
- 年齢が高ければ高い程浮気しやすい
今から年齢や婚姻期間を変更することはできませんので、私が取りうる対策は
- 奥さんの幸福度を高める
- 宗教に入信させる
であることが浮き彫りになったと、そんな結果になりました。
その他、pythonやkaggle、AI・機械学習といった記事のまとめはこちらです。
-
-
プログラミング関連の記事まとめ
続きを見る
ここからは、実際に私が購入し、おすすめできると思った本やオンラインスクールを紹介します。
機械学習のための「前処理」入門
まずはこちら。「機械学習のための『前処理』入門」です。
- これから機械学習を始めてみたい
- kaggleやSIGNATEにチャレンジしてみたい
という方には最適な本で、個人的には一番のおすすめです。
データモデルの精度向上には特徴量エンジニアリングが不可欠、というよりこれが全てと言っても過言ではありません。
各種環境準備の方法やコーディングの詳細に至るまで、誰にでも分かりやすく書かれています。
この一冊さえあれば、とりあえずkaggleにトライすることができます。
Udemy「みんなのAI講座 ゼロからPythonで学ぶ人工知能と機械学習」
ベネッセが主催する、プログラミング未経験者を対象にしたコース。
数学や統計的な知識はそこそこに、文字通り人工知能と機械学習をゼロから学習できます。
受講生2万人以上、4千人以上の評価者から、5段階中4.0の評価を得ている、万人におすすめできる優良講座。
定価15,000円と高価ですが、90%OFFといったキャンペーンを頻繁に行っていますので、それを狙うのがおすすめ。
人工知能は人間を超えるか
pythonのコーディングからは離れますが、もしこの本を読んでいない人がいたら必ず一度は目を通しておいた方が良いです。
この界隈では有名な、東大の松尾豊先生の著書「人工知能は人間を超えるか」。
いわゆるAI・人工知能、機械学習といった昨今のキーワードを中心に、過去の歴史からここ最近の動き、今後の動向に至るまでを、平易な表現で丁寧に解説されています。
また日本ディープラーニング協会が開催する「ディープラーニング ジェネラリスト検定(通称:G検定)」の推薦図書の一つでもあります。
全てのビジネスマンにおすすめできる一冊。中古でもkindleでも構いませんので、これだけは目を通しておいた方が良いです。