タップできるもくじ
【kaggle入門】GBDTによる最もシンプルな分類モデル構築

kaggle初心者あるあるですよね。
まずは最低限、
- 与えられたデータからモデルを構築する
- 予測をして、submitする
事にトライしましょう。
記事を書いた人
元営業という経歴を活かしながら、金融・製造・流通業のお客様を中心にAI活用コンサルや定着支援・人材育成の支援をしたり、講演や執筆活動など幅広く活動しています。
ヤエリ(@yaesuri_man)
普段のお客様との会話の中でよく話題に出るこのテーマ。
技術畑ではないものの、長らく現場の実務に携わってきた視点は喜ばれることが多いです。
GBDTの特長
使い勝手の良さと精度の高さから、コンペで多用されているGBDT(Gradient Boosting Decision Tree)。
その特長について簡単にまとめます。
GBDTの特長
- ハイパーパラメーターチューニングをしなくても精度が出やすい
- 数値特徴量にさえすれば、欠損値の補完は不要
- 各特徴量間の相互作用が反映される
- 特徴量間のスケールを気にする必要がない
各コンペでも、とりあえず一回目を回すために利用されています。
いつも通り、kaggleの初心者向けチュートリアル問題で最も有名な「タイタニック」を利用してコーディングしています。

言語はpython。kaggle上で無料で利用できる環境「Notebook」を利用しています。
New Notebookの作成
上記タイタニックのリンクから「New Notebook」を選択し、「python」「New Notebook」を選択すると、まずは以下のコードが現れます。
# This Python 3 environment comes with many helpful analytics libraries installed
# It is defined by the kaggle/python docker image: https://github.com/kaggle/docker-python
# For example, here's several helpful packages to load in
import numpy as np # linear algebra
import pandas as pd # data processing, CSV file I/O (e.g. pd.read_csv)
# Input data files are available in the "../input/" directory.
# For example, running this (by clicking run or pressing Shift+Enter) will list all files under the input directory
import os
for dirname, _, filenames in os.walk('/kaggle/input'):
for filename in filenames:
print(os.path.join(dirname, filename))
# Any results you write to the current directory are saved as output.
これは機械学習でよく使われる計算ライブラリ「numpy」と、データ分析ライブラリ「pandas」を読み出し、使える状態にするコードです。
(「numpy」を「np」、「pandas」を「pd」という名前でインポートしています)
この
import numpy as np
import pandas as pd
は、機械学習のコードを書く上でのお約束のようなもので、ほぼ必ず出てきます。
「#」より右の文字列は、コメント行。
最後の4行は、タイタニックのコンペフォルダに格納されているデータを表示するコードとなります。
上記セルを実行すると、以下のようにファイルのパスとファイル名が表示されます。
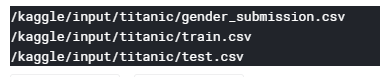
- train.csv・・・トレーニングデータ
- test.csv・・・予測用データ
- gender_submission.csv・・・結果投稿用のサンプルデータ
です。
必要なライブラリの読み込み
今回利用するライブラリをあらかじめ読み込んでおきます。
#各種ライブラリの読み込み from sklearn.preprocessing import LabelEncoder from xgboost import XGBClassifier
後から出てきますが、それぞれ以下です。
- LabelEncoder・・・カテゴリ値をエンコードするためのライブラリ
- XGBClassifier・・・GBDTのライブラリ「XGBoost」
データの読み込み
上記で表示されたデータを読み込みます。
#データの読み込み
train = pd.read_csv('../input/titanic/train.csv')
test = pd.read_csv('../input/titanic/test.csv')
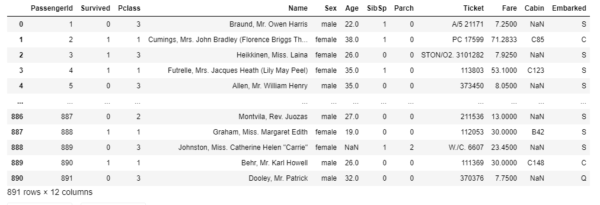
このコード自体は実行しても何も起こりません(ウンともスンとも言わない)ですが、以下コードを実行すれば、ちゃんとデータが読み込まれていることが分かります。
train
学習データを分離する
学習データには、「説明変数」と「目的変数」両方が含まれています。
- 「目的変数」・・・今回予測したい列(Survived)
- 「説明変数」・・・上記以外の列
この2つを分離し、「説明変数」を「train_x」、「目的変数」を「train_y」としておきます。
テストデータには「目的変数」は含まれないので、そのまま。
これを「text_x」とします。
#学習データを特徴量と目的変数に分ける train_x = train.drop(['Survived'], axis=1) train_y = train['Survived'] #テストデータは特徴量のみなので、そのまま test_x = test.copy()
文字列をエンコードする
冒頭で説明した通りGBDTは欠損値の補完は不要ですので、ここでは文字列のエンコードのみを実行します。
今回使うのは「LabelEncoder」。
もっともシンプルなエンコード手法です。
LabelEncordingは、とりあえず手っ取り早くモデルを作る際によく利用される方法で、カテゴリの値の序列を全く無視して数値変換するというもの。
例として、市区町村別の平均年収を予測するようなデータモデルを作るケースで説明します。
- 世田谷区
- 品川区
- 八王子市
- 奥多摩町
という4つのテキスト(カテゴリ値)を数字に変換する場合、
- 世田谷区→154
- 品川区→140
- 八王子市→192
- 奥多摩町→198
というように、「世田谷区と品川区は近い」「八王子市と奥多摩町は近い」という特徴表現を失わないようなエンコードがベストです。
(この例は郵便番号の上3桁でエンコードした例)
しかしLabelEncordingの場合は
- 世田谷区→1
- 品川区→2
- 八王子市→3
- 奥多摩町→4
というように、各値の序列を無視してエンコーディングします。
上記のように特徴表現を失わない形でエンコードしたい場合は、LabelEncordingではなく、それぞれ明示的に指定してあげるのがベストです。
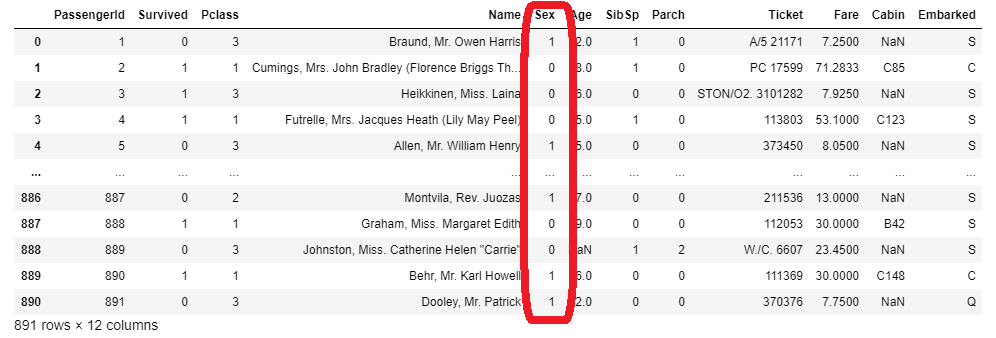
train,testそれぞれのデータフレームの列「Sex」をエンコーディングします。
列名の指定は大文字小文字も区別しますのでご注意下さい(「Sex」という列名なので、「sex」のように先頭が小文字だとエラーが出ます)
#文字列をエンコードする le = LabelEncoder() le = le.fit(train_x['Sex']) train_x['Sex'] = le.transform(train_x['Sex']) le = LabelEncoder() le = le.fit(test_x['Sex']) test_x['Sex'] = le.transform(test_x['Sex'])
実行してもぱっと見何も起きていませんが、trainを実行すると、ちゃんとエンコーディングされているのが分かります。
train_x
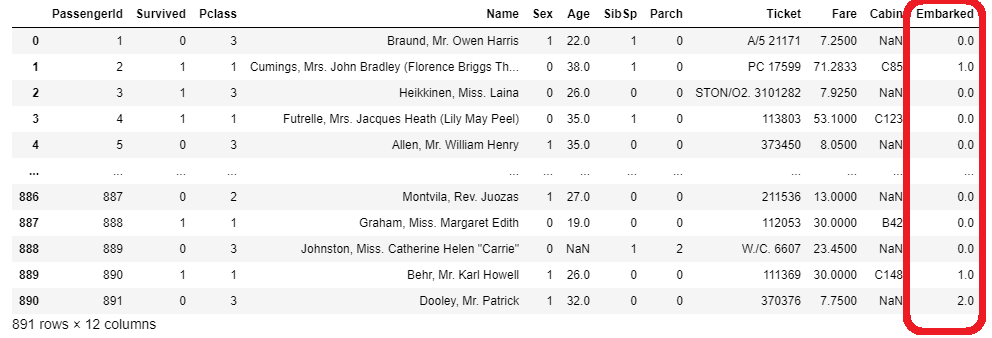
Embarkedの列については、試しに明示的にエンコードしてみます。
#明示的にエンコードする
embarked = {'S':0, 'C':1, 'Q':2}
train_x['Embarked'] = train_x['Embarked'].map(embarked)
test_x['Embarked'] = test_x['Embarked'].map(embarked)
Enbarkedの値を、S=0、C=1、Q=2と明示的に指定してあげた結果、以下のようになりました。
train_x
不要な列の削除
以下の列は不要である(生き残るかどうかには関係ない)と判断し、各データからごっそり削除します。
- PassengerID
- Name
- Ticket
- Cabin
#不要な列を削除する train_x.drop(['PassengerId', 'Name', 'Cabin', 'Ticket'], axis=1, inplace=True) test_x.drop(['PassengerId', 'Name', 'Cabin', 'Ticket'], axis=1, inplace=True)
以上の実行したデータを見てみると、
train_x
だいぶスッキリしてしまったものの、とりあえずモデリングに使えそうな前処理済みのデータが出来上がっていることが分かります。
モデリングする
モデルを作成し、学習データを加えて学習します。
#モデルの作成および学習データを与えての学習 model = XGBClassifier(n_estimators=20, random_state=71) model.fit(train_x, train_y)
後処理する
テストデータの予測値を確率で出力したうえ、0,1の二値に変換します。
※タイタニックコンペの場合、「生き残る確率=0.545」などの小数点だと受け付けてくれません
#テストデータの予測値を確率で出力する pred = model.predict_proba(test_x)[:, 1] #テストデータの予測値を0,1の二値に変換する pred_label = np.where(pred > 0.5, 1, 0)
提出用ファイルを作成する
最後に提出用のcsvファイルを生成して完了です。
#提出用ファイルの作成
submission = pd.DataFrame({'PassengerId': test['PassengerId'], 'Survived': pred_label})
submission.to_csv('submission_first.csv', index=False)
【kaggle入門】GBDTによる最もシンプルな分類モデル構築まとめ
一連の流れを一つのコードとしてまとめると以下です。
#各種ライブラリの読み込み
from sklearn.preprocessing import LabelEncoder
from xgboost import XGBClassifier
#データの読み込み
train = pd.read_csv('../input/titanic/train.csv')
test = pd.read_csv('../input/titanic/test.csv')
#学習データを特徴量と目的変数に分ける
train_x = train.drop(['Survived'], axis=1)
train_y = train['Survived']
#テストデータは特徴量のみなので、そのまま
test_x = test.copy()
#文字列をエンコードする
le = LabelEncoder()
le = le.fit(train['Sex'])
train_x['Sex'] = le.transform(train['Sex'])
le = LabelEncoder()
le = le.fit(test['Sex'])
test_x['Sex'] = le.transform(test['Sex'])
#明示的にエンコードする
embarked = {'S':0, 'C':1, 'Q':2}
train_x['Embarked'] = train['Embarked'].map(embarked)
test_x['Embarked'] = test['Embarked'].map(embarked)
#不要な列を削除する
train_x.drop(['PassengerId', 'Name', 'Cabin', 'Ticket'], axis=1, inplace=True)
test_x.drop(['PassengerId', 'Name', 'Cabin', 'Ticket'], axis=1, inplace=True)
#モデルの作成および学習データを与えての学習
model = XGBClassifier(n_estimators=20, random_state=71)
model.fit(train_x, train_y)
#テストデータの予測値を確率で出力する
pred = model.predict_proba(test_x)[:, 1]
#テストデータの予測値を0,1の二値に変換する
pred_label = np.where(pred > 0.5, 1, 0)
#提出用ファイルの作成
submission = pd.DataFrame({'PassengerId': test['PassengerId'], 'Survived': pred_label})
submission.to_csv('submission_first.csv', index=False)
まずはとにかく上記コードを活用してsubmitを目指す。
無事submitができたら、前処理を工夫するなどしてデータモデルの精度向上に精進しましょう。
【参考文献】
その他、pythonやkaggle、AI・機械学習といった記事のまとめはこちらです。
-

-
プログラミング関連の記事まとめ
続きを見る
ここからは、実際に私が購入し、おすすめできると思った本やオンラインスクールを紹介します。
機械学習のための「前処理」入門
まずはこちら。「機械学習のための『前処理』入門」です。
- これから機械学習を始めてみたい
- kaggleやSIGNATEにチャレンジしてみたい
という方には最適な本で、個人的には一番のおすすめです。
データモデルの精度向上には特徴量エンジニアリングが不可欠、というよりこれが全てと言っても過言ではありません。
各種環境準備の方法やコーディングの詳細に至るまで、誰にでも分かりやすく書かれています。
この一冊さえあれば、とりあえずkaggleにトライすることができます。
Udemy「みんなのAI講座 ゼロからPythonで学ぶ人工知能と機械学習」
ベネッセが主催する、プログラミング未経験者を対象にしたコース。
数学や統計的な知識はそこそこに、文字通り人工知能と機械学習をゼロから学習できます。
受講生2万人以上、4千人以上の評価者から、5段階中4.0の評価を得ている、万人におすすめできる優良講座。
定価15,000円と高価ですが、90%OFFといったキャンペーンを頻繁に行っていますので、それを狙うのがおすすめ。
人工知能は人間を超えるか
pythonのコーディングからは離れますが、もしこの本を読んでいない人がいたら必ず一度は目を通しておいた方が良いです。
この界隈では有名な、東大の松尾豊先生の著書「人工知能は人間を超えるか」。
いわゆるAI・人工知能、機械学習といった昨今のキーワードを中心に、過去の歴史からここ最近の動き、今後の動向に至るまでを、平易な表現で丁寧に解説されています。
また日本ディープラーニング協会が開催する「ディープラーニング ジェネラリスト検定(通称:G検定)」の推薦図書の一つでもあります。
全てのビジネスマンにおすすめできる一冊。中古でもkindleでも構いませんので、これだけは目を通しておいた方が良いです。